Yönetici Claude, İşçi Yerel LLM: Token Yakmadan Claude Kalitesinde Üretim
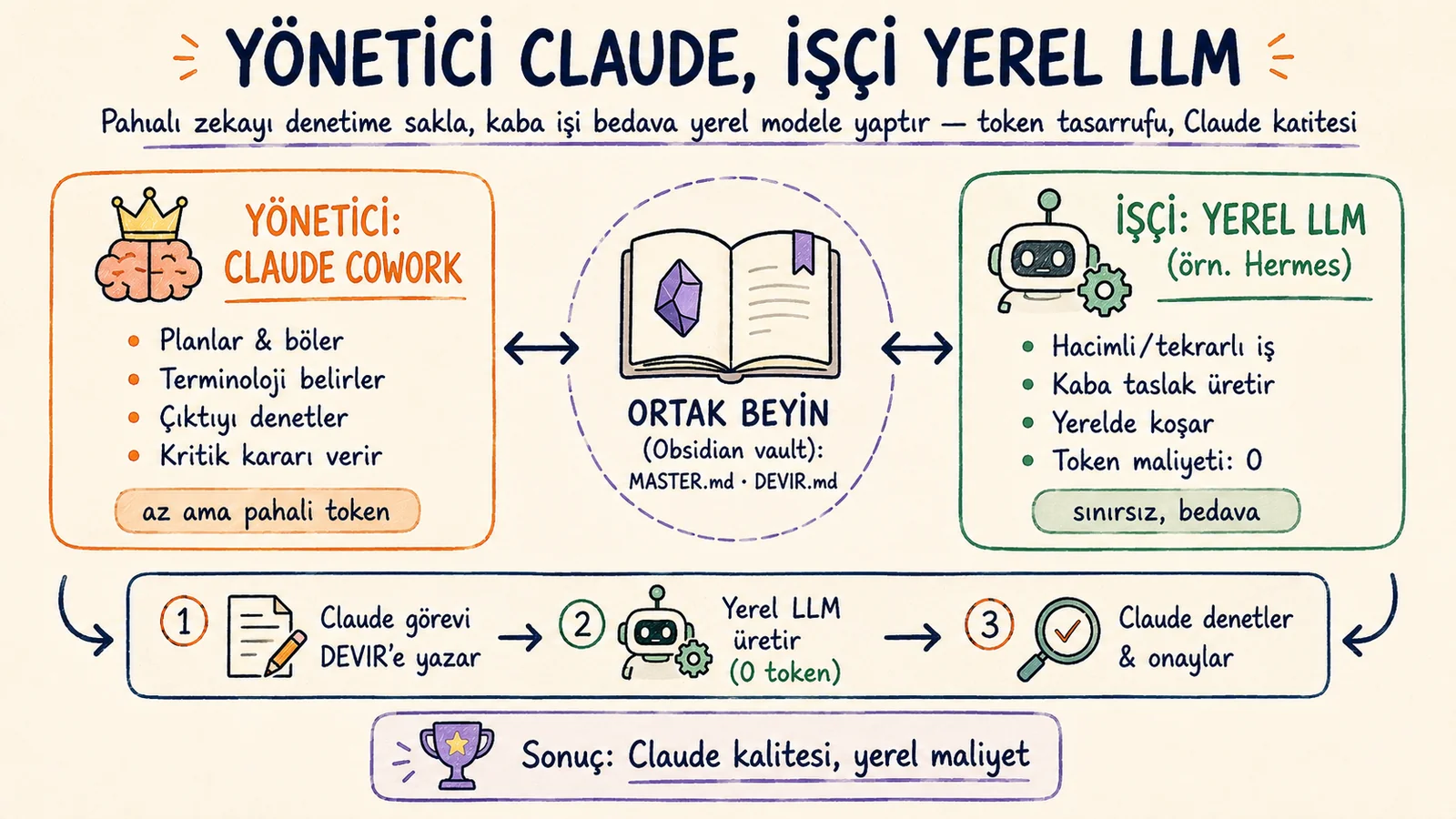
Claude pahalı ve limitli, yerel LLM bedava ama kalitesiz. İkisini birleştir: yönetici Claude planlar ve denetler, işçi yerel model hacmi üretir. Ortak Obsidian beyniyle kurulum.
Claude'la çalışırken en sinir bozucu an: tam akış tutmuşken gelen "limit doldu" uyarısı. Kaliteyi seviyorsun ama her işi ona yaptırmak hem pahalı hem limitli. Öbür uçta yerelde çalışan bedava bir model var — sınırsız, ama tek başına o kaliteyi tutturamıyor.
Çözüm ikisini de bırakmak değil, aralarında iş bölümü yapmak: Claude'u yönetici, yerel modeli işçi yap. Claude planlar ve denetler; hacimli kaba işi token yakmadan yerel model çıkarır. İkisini de aynı beyne — bir Obsidian klasörüne — bağlarsın; biri yazar, öteki okur.
Bunu kurup çalıştırdım. Aşağıda adım adım nasıl yapacağın, hangi modeli seçeceğin ve nerede zorlanacağın var.
"Cowork ve Hermes zaten çok-ajanlı — buna ne gerek var?"
Haklı soru. Claude Cowork tek başına birçok alt görevi yönetebiliyor, yerelde koşan bir agent da öyle. Ama mesele "çok ajan" değil — mesele hangi işi hangi zekaya yaptırdığın.
Çünkü her token eşit pahada değil. Claude'a 40 araç açıklamasını tek tek çevirtirsen, en sıradan cümleler bile premium tokeni![]() modelin işlediği metin birimi; faturanın ve limitin temeli yakar ve kotan yarılanır. Oysa o 40 çevirinin kaba taslağını yerelde koşan bir modele yaptırırsan maliyet sıfır; Claude'a sadece planlama ve son kalite kontrolü kalır.
modelin işlediği metin birimi; faturanın ve limitin temeli yakar ve kotan yarılanır. Oysa o 40 çevirinin kaba taslağını yerelde koşan bir modele yaptırırsan maliyet sıfır; Claude'a sadece planlama ve son kalite kontrolü kalır.
Ayrım tam da burada:
- Yönetici (Claude Cowork): düşünür, işi böler, terminolojiyi belirler, çıktıyı denetler, kritik kararı verir.
- İşçi (yerel LLM'de koşan agent): hacimli, tekrarlı, düşük riskli işi token yakmadan üretir.
Sonuç: Claude kalitesinde iş, ama token'ın çoğunu bedava yerel model yemiş olur. Üstüne bonus: her şey senin diskinde döner — buluta da bir git reposuna da muhtaç değilsin, dolayısıyla veri dışarı sızmaz.
[mindi_yorum]
💰 Yerel modelin token maliyeti sıfır (kendi donanımında çalışır). Pahalı premium token'ı yalnızca planlama + denetime saklarsın.
🟢 Limit derdi biter: hacim işi yerele kayar, Claude'un kotası kritik işlere kalır.
🟡 Yerel modelin kalitesi sınırlı — kritik veya ince işi ona bırakma, sadece kaba taslak ve hacim ver.
🔵 Altın kural: "üreten yerel, onaylayan Claude". Yerel üretir, Claude son sözü söyler.
1. Obsidian vault'unu oluştur (ortak beyin)
Önce iki ajanın buluşacağı klasörü kuracaksın. Obsidian bunun için ideal, çünkü her şeyi düz markdown olarak yerelde tutar — özel bir format yok, kaybolma riski yok.
Obsidian'ı indir ve kur (kişisel kullanımda ücretsiz). İlk açtığında bir karşılama ekranı gelir; orada "Create new vault" ve "Open folder as vault" seçeneklerini görürsün. Vault dediği şey aslında sadece bir klasör — Obsidian o klasörün içindeki notları yönetir ve içine küçük bir .obsidian ayar klasörü ekler. Sihir yok, sıradan bir dizin.
İki yol var, ikisi de aynı kapıya çıkar:
Yol A — Obsidian oluştursun. Karşılama ekranında "Create new vault" de. Bir isim ver (örneğin beyin), konum olarak Masaüstü'nü seç, "Create" bas. Obsidian Masaüstünde beyin klasörünü açar.
Yol B — Klasörü sen aç. Masaüstüne sağ tıkla → Yeni → Klasör, adını beyin koy. Sonra Obsidian'da "Open folder as vault" de ve bu klasörü seç.
Her iki durumda da elinde Masaüstünde, ajanların konuşacağı .md dosyalarını barındıracak bir beyin klasörü olur. İçine birazdan MASTER.md (kurallar) ve DEVIR.md (mesajlaşma) koyacaksın — ama önce bu klasörü yöneticiye tanıtalım.
2. Vault yolunu Claude Cowork'e ver
Claude Cowork dosyalarınla doğrudan senin diskinde çalışır; ona "çalışma alanın şu klasör" demen yeterli. Bunun için klasörün tam yolunu kopyalarsın:
Windows'ta: Masaüstündeki beyin klasörüne gir. Üstteki adres çubuğunda boş bir yere tıkla — yol metin olarak seçili gelir (örn. C:\Users\adin\Desktop\beyin), kopyala. Alternatif: klasöre Shift tuşu basılıyken sağ tıkla → "Yol olarak kopyala".
Mac'te: Finder'da beyin klasörüne sağ tıkla, Option (⌥) tuşunu basılı tut → "beyin öğesini yol adı olarak kopyala".
Sonra Claude Cowork'te bu klasörü çalışma alanı olarak ekle ya da kopyaladığın yolu yapıştır. Cowork klasörü okuma/yazma izni ister; onaylarsın. Artık yöneticin beyne bağlı: MASTER.md'yi okur, DEVIR.md'ye iş yazar.
3. İşçiyi bağla: yerel LLM'de bir agent (örn. Hermes)
İşçi tarafında, yerelde çalışan bir agenti![]() çok adımlı görevleri kendi yürüten AI devreye girer. Ben burada Hermes diye, kendi makinemde koşan yerel bir modele bağlı bir agent kullanıyorum — sen hangi yerel agent'ı kullanıyorsan o olur, mantık aynı.
çok adımlı görevleri kendi yürüten AI devreye girer. Ben burada Hermes diye, kendi makinemde koşan yerel bir modele bağlı bir agent kullanıyorum — sen hangi yerel agent'ı kullanıyorsan o olur, mantık aynı.
İşçiyi bağlamak yöneticiyle birebir aynı: agent'ın system prompti![]() bir AI'a en baştan verilen kalıcı davranış talimatı'una "çalışma alanın şu klasör, başında oku, sonunda yaz" dersin.
bir AI'a en baştan verilen kalıcı davranış talimatı'una "çalışma alanın şu klasör, başında oku, sonunda yaz" dersin.
Çalışma alanın: C:\Users\adin\Desktop\beyin
Oturum başında MASTER.md ve DEVIR.md'de sana gelen şeridi oku.
İş bitince ürettiğini DEVIR.md'de karşı şeride yaz.
MASTER.md'yi değiştirme.
Hermes yerel modelde koştuğu için bu işçiye iş yaptırmak sana token'a mal olmaz — elektrik dışında bedava. Ama her yerel model her işi kaldırmaz; doğru boyutu seçmek bu sistemin can damarı.
4. Hangi yerel modeli seçersin? (donanıma göre)
Modeli çalıştırmak için bir yerel runtime kullanırsın — ben LM Studio örnekliyorum, ama Ollama da aynı işi görür. Altın kural net: modelin boyutunu VRAM'in belirler. Model büyüdükçe kalite artar, ama GPU belleğine (VRAM) sığmazsa iş CPU'ya taşar ve sürünür. Kademeler:
- 3-4B (Q4, ~2-3 GB VRAM): çok hızlı, düşük donanım yeter. Ama Türkçe üretimde zayıf — çeviri bozuk, kelimeler uyduruk çıkabiliyor. Sadece dile duyarsız hacim işine koş: etiketleme, sınıflandırma, JSON ayıklama.
- 7-8B (Q4, ~5 GB VRAM): tatlı nokta. Türkçesi "yönetici rötuşlar, sıfırdan yazmaz" seviyesinde. Genel işçi için bunu seç. Somut öneri: Qwen2.5-7B-Instruct — düz Instruct sürümü (Vision/Coder/Math değil).
- 14B+ (Q4, 10+ GB VRAM): en iyi Türkçe, ama güçlü GPU şart; 6 GB'lık bir makinede her sorgu dakikalar sürer.
Bunu bizzat denedim: 6 GB VRAM'li bir dizüstüde 4B hızlıydı ama Türkçesi kullanılamazdı ("AI yazı ayutcusu" gibi cümleler çıktı); 20B'lik bir model kaliteliydi ama o makineye sığmadığı için sürünüyordu. İkisinin ortası — 7B — Türkçe üretim için makul başlangıç.
LM Studio ayarları: quant Q4_K_M, GPU Offload mümkün olduğunca yüksek, context 4096, Flash Attention açık. İndirirken modelin düz Instruct sürümünü seç; "VL/Vision" görsel modeldir, çeviri için boşuna ağırdır.
Donanımın 7B'yi zorluyorsa işçiyi buluta taşı ama yine bedava kalabilirsin: OpenRouter'ın :free modelleri. Hesap açıp API anahtarı alırsın (kredi kartı istemez), model kimliğinin sonundaki :free etiketi o modelin ücretsiz olduğunu gösterir. Türkçe hacim işi için şu an en güçlü ücretsiz seçenek GPT-OSS 120B (:free) — kendi makinende asla çalıştıramayacağın boyutta bir model, bedavaya işçin oluyor. Bizzat test ettim: Nemotron 3 120B (:free) otomatik kurulumda bir çeviri görevini ~19 saniyede, sıfır maliyetle ve "rötuşla geçer" Türkçeyle döndürdü — kendi makinende asla koşamayacağın bir model, bedava işçin oldu. İki uyarı: ücretsiz katmanda günde ~200 istek, dakikada 20 sınırı var (çok büyük batch'te yetmeyebilir), ve bulut olduğu için "her şey diskimde" gizlilik avantajını kaybedersin. Liste sık değişiyor — OpenRouter model sayfasında "Free" filtresinden güncelini doğrula. İşçiyi agent'ında OpenRouter'a yönlendirmen yeterli; mimari aynen çalışır, yönetici yine Claude'da kalır.
5. İş akışı: yönetici yazar, işçi yapar, yönetici denetler
Sistem artık dönüyor. Tipik bir döngüyü somutlaştıralım: diyelim 40 araç açıklamasını Türkçeleştireceksin. Hepsini Claude'a yaptırsan kotan biter. Bunun yerine:
- Claude (yönetici) terminolojiyi ve format kurallarını belirler, "şu 40 metni şu kurallarla çevir" diye
DEVIR.md'ye yazar. - İşçi 40 çeviriyi yerel modelde üretir, çıktıyı
DEVIR.md'ye bırakır — sıfır Claude token. - Claude (kontrolör) çıktıyı okur, terminolojiye uymayan birkaçını düzeltir, onaylar.
Sonuç: Claude kalitesinde 40 çeviri, ama premium token'ın yalnızca planlama ve denetim kadarı harcandı. Hacim arttıkça tasarruf da büyür.
Bir tuzak var, kanım pahasına öğrendim: işçiye context'i şişirme. Modele tüm vault'u, hafızayı, geçmişi gönderirsen yerel model her çağrıda binlerce token'lık prompt'u işler ve LM Studio'da hızlıyken API üzerinden sürünür. Çözüm: işçiye yalnızca o işin metnini ve kurallarını yolla — fazlasını değil. Kısa brief, hızlı işçi.
[mindi_yorum]
💰 Claude Cowork araştırma önizlemesinde, Pro/Max planında; yerel işçi kendi donanımında bedava. Maliyetin neredeyse tamamı yöneticide kalır, o da az ve kritik token harcar.
🟢 Ölçek büyüdükçe kazanç artar: 5 iş değil 500 iş yapacaksan fark uçurum olur.
🟡 Denetimi atlama. Yerel çıktıyı "nasılsa olmuştur" deyip geçersen kalite çöker — yöneticinin kontrolü bu sistemin sigortası. Ayrıca model çok zayıfsa (4B Türkçe gibi) düzeltmek sıfırdan yazmak kadar pahalıya gelir; tasarruf ancak işçi "yeterince iyi" ise gerçekleşir.
🔵 İşçiye net brief ver (terminoloji + format + bir örnek). Brief ne kadar netse, düzeltme o kadar az.
İşçiyi kim tetikler? (çoğu anlatımın atladığı yer)
Burada kritik bir boşluk var: Claude görevi DEVIR.md'ye yazar, peki işçi onu ne zaman görür? Dosya tabanlı bir beyinde yöneticinin işçiyi otomatik dürten bir kolu yoktur — işçinin tetiklenmesi gerekir. İki yol:
1. İnsan tetikli (önerilen başlangıç). Claude görevi yazar, sen işçiye "DEVIR'i oku ve yap" dersin. Kulağa ilkel geliyor ama aslında bir özellik: hangi görevin ne zaman koşacağı sende, yanlış iş kendiliğinden çalışmaz. Kişisel kurulumların çoğu böyle yürür.
2. Otomatik (polling / dosya-izleme). İşçiyi bir döngüde ya da zamanlanmış görevde çalıştır: her birkaç dakikada DEVIR'in kendine gelen şeridini tarasın, yapılmamış görev varsa koşsun, bitince işaretlesin. Şartı şu — her göreve bir durum etiketi koy, örneğin başlığa ⬜ (bekliyor) / ✅ (bitti). Yoksa işçi aynı görevi her turda baştan yapar. Dosya değiştiğinde tetikleyen bir izleyici (watcher) de aynı işi görür.
Pratik tavsiye: 1 ile başla. Akış oturup güvendiğinde 2'ye geç. Otonomi havalı ama denetimsiz işçi yanlış işi hızla çoğaltır.
Bunu kurup canlı denedim: vault'u izleyen ~60 satırlık küçük bir script (worker), Claude ⬜ işaretli bir görev yazınca onu yakalıyor, doğrudan buluttaki modele (OpenRouter, ücretsiz Nemotron 120B) yolluyor, cevabı işçi → yönetici şeridine yazıp görevi ✅'liyor. Yani tetik basitçe "dosyaya yazmak"; işçi de bu script + bulut model. Bir çeviri görevi ~19 saniyede, sıfır maliyetle döndü.
Protokol: kim ne okur, ne yazar
Tek doğruluk kaynağı MASTER.md'dir ve onu yalnızca yönetici (Claude) günceller. DEVIR.md iki şeritli bir mektup kutusudur: herkes kendi giden şeridine yazar, karşınınkini okur — böylece aynı dosyaya yazarken birbirini ezmezler. Önemli kararlar KARAR-LOGU.md'ye düşer. Çelişki çıkarsa MASTER.md doğrudur.
Bu kadar az kuralın yetmesinin sebebi rollerin net olması: biri yönetir, biri üretir, ikisi de nereye bakacağını tartışmasız bilir.
Sonuç: şimdi ne yaparsın
- Obsidian'ı kur, Masaüstünde
beyinadında bir vault oluştur. - İçine
MASTER.md(kurallar + terminoloji) veDEVIR.md(iki boş şerit) koy. - Klasörün yolunu kopyala, Claude Cowork'e çalışma alanı olarak ver — yöneticin hazır.
- VRAM'ine uygun bir model kur (6-8 GB için Qwen2.5-7B-Instruct, Q4_K_M iyi başlangıç; makinen yetmezse OpenRouter
:free), işçine "başta oku, sonda yaz" talimatını ver — işçin hazır. - Küçük bir işle test et: Claude
DEVIR'e beş maddelik bir görev yazsın, işçi yapsın, Claude denetlesin. Döngü dönüyorsa sistemi büyüt.
Mantık tek cümle: pahalı zekayı düşünmeye ve denetime sakla, kaba işi ucuz (tercihen yerel) modele yaptır. Token'ın korunur, kalite Claude'da kalır. Küçük başla — bir yönetici, bir işçi, iki dosya.